Los modelos de lenguaje de visión son ciegos.
Los modelos de lenguaje de gran tamaño con capacidades visuales (VLM), por ejemplo, GPT- 4o y Gemini- 1.5 Pro , están impulsando innumerables aplicaciones de procesamiento de texto e imágenes y están obteniendo altas puntuaciones en los parámetros de comprensión visual existentes. Sin embargo, descubrimos que los VLM fallan en siete tareas visuales absurdamente fáciles para los humanos, como identificar (a) si dos círculos se superponen; (b) si dos líneas se cruzan; (c) qué letra está rodeada en una palabra; y (d) contar la cantidad de círculos en un logotipo de estilo olímpico. El desempeño sorprendentemente pobre de cuatro VLM de última generación sugiere que su visión es, en el mejor de los casos, como la de una persona con miopía que ve los detalles finos borrosos y, en el peor, como la de una persona inteligente que es ciega y hace conjeturas fundamentadas.
Tarea 1
Tarea 1: Contar intersecciones de líneas
Dada la impresionante precisión de los VLM al responder preguntas sobre diagramas y gráficos (por ejemplo, Sonnet- 3.5 obtuvo un 94,7 % en AI2D y un 90,8 % en ChartQA) [1] , una hipótesis razonable es que los VLM deben poder ver si dos gráficos se intersecan en un gráfico. Aquí, probamos esta hipótesis pidiendo a los VLM que cuenten la cantidad de intersecciones entre dos funciones lineales por partes de 2 segmentos.
Imágenes
Creamos 150 imágenes (ver Figura 1) de gráficos de líneas 2D dibujados en un lienzo blanco. Cada gráfico de líneas consta de dos segmentos de línea, definidos por tres puntos cuyas coordenadas x son fijas y están espaciadas de manera uniforme. Las coordenadas y se toman aleatoriamente para crear dos gráficos que se intersecan exactamente en 0, 1 o 2 puntos. Ver Apéndice A para más detalles.




Fig. 1: Ejemplos de gráficos de líneas 2D utilizados en la tarea, que muestran diferentes números de intersecciones.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «¿Cuántas veces se cruzan las líneas azul y roja?»
- «¿Cuántas veces se cruzan las líneas azul y roja?»
Verdad fundamental
Las respuestas son ∈ {0, 1, 2} (precisión de referencia aleatoria: 33%).
Resultados
La siguiente tabla muestra el desempeño de los cuatro modelos en la tarea de contar intersecciones de líneas.
| Espesor |
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|---|---|---|---|---|
| 2 | 45,00 | 70,00 | 64.00 | 80.00 |
| 3 | 47,00 | 68,00 | 66,00 | 79,00 |
| 4 | 54,00 | 71,00 | 62,00 | 73,00 |
| Promedio | 48,67 | 69,67 | 64.00 | 77.33 |
Muestras cualitativas
¿Cuantas veces se cruzan las lineas azul y roja?
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
| 1✗ | 1✗ | 2✗ | 2✓ | 2✓ | 1✗ | |
| 1✗ | 1✗ | 1✓ | 1✗ | 1✗ | 1✗ | |
| 1✗ | 1✗ | 2✗ | 1✗ | 1✗ | 1✗ | |
 |
1✗ | 0✓ | 2✗ | 1✗ | 1✗ | 2✓ |
Soneto- 3.5Fig. 2: Los VLM no pueden contar las intersecciones de manera confiable.
Tarea 2: Dos círculos
A diferencia de la tarea 1, en la que probamos los VLM con líneas finas, aquí evaluamos su capacidad para percibir interacciones entre objetos más grandes, específicamente, dos círculos rellenos del mismo tamaño. Esta tarea evalúa la capacidad de los VLM para detectar (1) pequeños espacios entre círculos y (2) círculos superpuestos.
Imágenes
Generamos 672 imágenes de dos círculos sobre un lienzo blanco. Los círculos varían en tamaño, distancia y orientación:
- Diámetros de los círculos: 1/4, 1/5, 1/6 o 1/7 del tamaño del lienzo.
- Distancias entre perímetros de círculos: -0,15 a 0,5 veces el diámetro
- Orientaciones: ángulos de 90°, 0°, -45° y 45° con el eje x
- Tamaños de lienzo: 384, 769 y 1155 píxeles
Fig. 3: Ejemplos de imágenes de dos círculos utilizadas en la tarea, que muestran diferentes configuraciones.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «¿Los dos círculos se tocan entre sí? Responda Sí/No».
- «¿Los dos círculos se superponen? Responda Sí/No».
Verdad fundamental
Las respuestas se basan en la distancia d entre los perímetros de los círculos:
- d < 0: Superposición y contacto
- d = 0: No se superponen pero se tocan
- d > 0: Sin superposición y sin contacto
Precisión de línea base aleatoria: 50%.
Resultados
La siguiente tabla muestra el desempeño de los cuatro modelos en la tarea de contar intersecciones de líneas.
|
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|
|---|---|---|---|---|
| Superposición | 71.27 | 93.30 | 88.09 | 88,83 |
| Conmovedor | 74.10 | 92.26 | 80,95 | 94,49 |
| Promedio | 72,69 | 92,78 | 84,52 | 91,66 |
Muestras cualitativas
¿Se superponen los dos círculos? Responda Sí/No.
| Sí✓ | Sí✓ | Sí✗ | Sí✗ | No✓ | Sí✗ | |
| No✗ | Sí✓ | Sí✗ | No✓ | No✓ | No✓ | |
| Sí✓ | Sí✓ | Sí✗ | Sí✗ | Sí✗ | No✓ | |
|
No✗ | No✗ | No✓ | No✓ | No✓ | No✓ |
Soneto- 3.5Fig. 4: Los VLM fallan sistemáticamente a distancias más pequeñas. Sin embargo, con una gran brecha, GPT- 4o sigue siendo poco confiable (extremo derecho). Sonnet- 3.5 tiende a responder «No» de manera conservadora, independientemente de la distancia real entre los dos círculos.
Tarea 3: La letra en un círculo
En consonancia con informes anteriores [2] [3] [4] , descubrimos que los VLM pueden identificar con un 100 % de precisión una forma primitiva (por ejemplo, un círculo rojo ⭕) [2] y pueden leer perfectamente una palabra en inglés (por ejemplo, Subdermatoglyphic ) por sí solos. Aquí, superpusimos el círculo rojo en cada letra, una a la vez, en la palabra, y pedimos a los VLM que identificaran qué letra estaba siendo encerrada en un círculo. Si bien la tarea es fácil para los humanos, nuestra hipótesis es que si la visión de un VLM es «borrosa», es posible que no pueda identificar la letra exacta que está siendo encerrada en un círculo, ya que hay un espacio diminuto entre las letras adyacentes.
Imágenes
Elegimos tres cadenas Acknowledgement , Subdermatoglyphic y tHyUiKaRbNqWeOpXcZvM porque contienen caracteres de anchos y alturas variables. Además, los cuatro VLM probados pueden leer todos los caracteres de estas cadenas cuando se ingresan a los modelos como una imagen. Si bien Acknowledgement es una palabra común en inglés, Subdermatoglyphic es la palabra más larga sin letras repetidas. También probamos los VLM en la cadena aleatoria tHyUiKaRbNqWeOpXcZvM para estimar cuánta precisión del modelo se debe a su familiaridad con la palabra.
Para cada par (cadena, letra en círculo), generamos una imagen de 512 × 512 eligiendo entre 3 niveles de grosor de línea de óvalo rojo, 2 tamaños de fuente y 4 posiciones aleatorias en el lienzo para un total de 24 imágenes. Es decir, generamos 360, 408 y 480 imágenes para Acknowledgement (15 letras), Subdermatoglyphic (17 letras) y tHyUiKaRbNqWeOpXcZvM (20 letras), respectivamente. Nos aseguramos de que cada letra que se encierre en un círculo se ajuste completamente al óvalo.


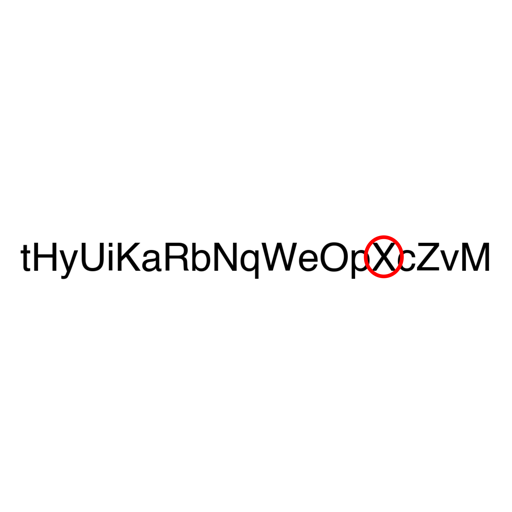

Fig. 5: Ejemplos de imágenes de letras en círculos utilizadas en la tarea, que muestran diferentes palabras y letras en círculos.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «¿Qué letra está marcada con un círculo?»
- «¿Qué personaje está resaltado con un óvalo rojo?»
Verdad fundamental
Las letras deben coincidir exactamente con las letras previstas (sin distinguir entre mayúsculas y minúsculas).
Resultados
La siguiente tabla muestra el desempeño de los cuatro modelos en la tarea de identificar la letra encerrada en un círculo.
| Palabra |
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|---|---|---|---|---|
| Reconocimiento | 69.03 | 97,50 | 82,64 | 91.11 |
| Subdermatoglifico | 63,60 | 91.05 | 71,45 | 94,49 |
| tuUiKaRbNqWeOpXcZvM | 77,92 | 89,90 | 65,94 | 82.08 |
| Promedio | 70,18 | 92,81 | 73.34 | 89.22 |
Muestras cualitativas
¿Qué letra está encerrada en un círculo?
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
| o✗ | mi✗ | a✗ | o✗ | o✗ | el✗ | |
| el✗ | metro✓ | norte✓ | pag✓ | o✗ | en✓ | |
| o✗ | mi✗ | mi✗ | y✗ | a✗ | a✗ | |
|
yo✓ | mi✗ | a✗ | yo✗ | a✓ | metro✗ |
Soneto- 3.5Fig. 6: Identificar la letra encerrada en un círculo no es una tarea trivial para los VLM tanto en palabras en inglés ( Acknowledgement y Subdermatoglyphic ) como en una cadena aleatoria ( tHyUiKaRbNqWeOpXcZvM ). Cuando cometen errores, los VLM tienden a predecir las letras adyacentes a la encerrada en un círculo.
Tarea 4: Contar formas superpuestas
En consonancia con investigaciones anteriores [4] , también descubrimos que los VLM pueden contar círculos disjuntos. Sin embargo, aquí, probamos los VLM para contar círculos que se intersecan como en el logotipo olímpico, un ejercicio de desarrollo cognitivo común para niños en edad preescolar [5] [6] . Nuestra hipótesis es que una visión «borrosa» puede no ver claramente la intersección entre dos círculos y, por lo tanto, no puede trazar círculos y contarlos. Para generalizar nuestros hallazgos, repetimos el experimento también con pentágonos.
Imágenes
En una imagen de tamaño C×C, donde C ∈ {384, 769, 1155} px, dibujamos N ∈ {5, 6, 7, 8, 9} círculos superpuestos del mismo tamaño dispuestos en dos filas como el logo olímpico. Un diámetro de círculo φ ∈ {C/5, C/10}. Repetimos las imágenes con dos grosores de línea diferentes para representar los círculos. Este procedimiento representa 3 resoluciones × 5 × 2 diámetros = 60 imágenes. Repetimos para los pentágonos además de los círculos, lo que da como resultado 60 × 2 formas = 120 imágenes en total. Para los pentágonos, la longitud de sus lados es d ∈ {C/5, C/10}.
Fig. 7: Ejemplos de imágenes de logotipos similares a los olímpicos utilizados en la tarea, que muestran diferentes cantidades de formas, tamaños y colores.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «¿Cuántas formas hay en la imagen? Responde solo con el número en formato numérico».
- «Cuenta las {formas} de la imagen. Responde con un número entre llaves, p. ej. {3}».
Donde {formas} son «círculos» o «pentágonos» dependiendo de la imagen.
Verdad fundamental
Las respuestas son ∈ {5, 6, 7, 8, 9} (precisión de referencia aleatoria: 20%).
Resultados
La siguiente tabla muestra el desempeño de los cuatro modelos en la tarea de identificar la letra encerrada en un círculo.
|
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|
|---|---|---|---|---|
| Círculos | 42,50 | 20.83 | 31,66 | 44,16 |
| Pentágonos | 19.16 | 9.16 | 11.66 | 75,83 |
Muestras cualitativas
¿Cuántos círculos hay en la imagen? Responde solo con el número en formato numérico.
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
| 5✗ | 6✓ | 5✗ | 10✗ | 10✗ | 5✗ | |
| 5✗ | 5✗ | 5✗ | 5✗ | 5✗ | 5✗ | |
| 5✗ | 5✗ | 5✗ | 10✗ | 10✗ | 5✗ | |
|
5✗ | 6✓ | 6✓ | 10✗ | 9✓ | 7✓ |
Soneto- 3.5Fig. 8: Gemini- 1.5 Pro a menudo predice círculos «5».
Tarea 5: Contar los cuadrados anidados
Motivados por los hallazgos de que los VLM tienen dificultades para contar los círculos intersectados (tarea 4), aquí, organizamos las formas de manera diferente para que sus bordes no se intersequen. Es decir, cada forma está anidada completamente dentro de otra. Para completar, probamos cuadrados en esta tarea.
Imágenes
En un lienzo de tamaño C×C, renderizamos N ∈ {2, 3, 4, 5} cuadrados anidados. El cuadrado más externo se renderiza primero utilizando una longitud de borde aleatoria d y un grosor de línea ∈ {2, 3, 4}px. Los N-1 cuadrados restantes se dibujan utilizando un factor de reducción de tamaño, 0,75 × d y se colocan en una coordenada aleatoria que garantiza que no toquen los cuadrados externos. Para cada grosor de línea, generamos 10 imágenes (donde los cuadrados tienen diferentes ubicaciones aleatorias) para crear 3 × 10 = 30 imágenes. Repetir el proceso para todos los valores N da como resultado 4 × 30 = 120 imágenes.




Fig. 9: Ejemplos de imágenes cuadradas anidadas utilizadas en la tarea, que muestran diferentes cantidades de cuadrados.
Indicaciones
Planteamos cada pregunta utilizando el siguiente texto:
- «Cuenta el número total de cuadrados en la imagen».
Donde {formas} son «círculos» o «pentágonos» dependiendo de la imagen.
Verdad fundamental
Las respuestas son ∈ {2, 3, 4, 5} (precisión de referencia aleatoria: 25%).
Resultados
La siguiente tabla muestra el desempeño de los cuatro modelos en la tarea de contar cuadrados anidados.
|
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|
|---|---|---|---|---|
| Cuadrícula | 48.33 | 80.00 | 55,00 | 87,50 |
Muestras cualitativas
Cuente el número total de cuadrados en la imagen.
 |
|
 |
 |
 |
|
|
|---|---|---|---|---|---|---|
| 5✗ | 5✗ | 5✗ | 5✗ | 6✗ | 6✗ | |
| 5✗ | 5✗ | 5✗ | 5✗ | 5✓ | 5✓ | |
| 5✗ | 5✗ | 5✗ | 5✗ | 4✗ | 4✗ | |
|
4✓ | 4✓ | 4✓ | 4✓ | 4✗ | 4✗ |
Soneto- 3.5Fig. 10: Sólo Sonnet- 3.5 puede contar los cuadrados en la mayoría de las imágenes.
Tarea 6: Contar las filas y columnas de una cuadrícula
Los resultados de las tareas anteriores muestran que los VLM no siempre pueden contar formas superpuestas (Tarea 4) o anidadas (Tarea 5). ¿Qué sucede con las formas adyacentes? Aquí, colocamos las formas (específicamente, cuadrados) en una cuadrícula y desafiamos a los VLM a contar, una tarea que supuestamente es simple para los VLM dado su desempeño notable (≥ 90% de precisión) en DocVQA, que incluye muchas preguntas con tablas. Para simplificar la tarea, les pedimos a los modelos que cuenten la cantidad de filas y columnas en una tabla dada.
Imágenes
Una cuadrícula puede tener N×N, N×N’ o N’×N celdas, donde N∈{3, 4, 5, 6, 7, 8, 9} y N’ = N + 1. Cada cuadrícula se representa con dos grosores de línea diferentes en un lienzo de tamaño C×C donde C∈{500, 1250, 2000}px. Además de las cuadrículas vacías, también replicamos el procedimiento para hacer que las cuadrículas contengan texto (lo que es más común en las tablas del mundo real) donde cada celda contiene una sola palabra aleatoria. Las dos versiones combinadas tienen 2×222 = 444 imágenes.




Fig. 9: Ejemplos de imágenes de cuadrícula utilizadas en la tarea, que muestran cuadrículas llenas de texto y vacías con varias dimensiones.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «Cuente la cantidad de filas y columnas y responda con los números entre llaves. Por ejemplo, filas={5} columnas={6}»
- «¿Cuántas filas y columnas hay en la tabla? Responda sólo con los números de un par (fila, columna), por ejemplo, (5,6)»
Verdad fundamental
Las respuestas incluyen tanto el número de filas como de columnas. Una respuesta es correcta cuando se predicen correctamente tanto el número de filas como de columnas.
Resultados
La siguiente tabla muestra el rendimiento de los cuatro modelos en la tarea de contar filas y columnas en cuadrículas.
| Tipo de cuadrícula |
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|---|---|---|---|---|
| Blanco | 26.13 | 25,75 | 25,00 | 59,84 |
| Texto | 53.03 | 45,83 | 47.34 | 88,68 |
| Promedio | 39,58 | 35,79 | 36.17 | 74,26 |
Muestras cualitativas
Cuente la cantidad de filas y columnas y responda con los números entre llaves. Por ejemplo, filas={5} columnas={6}
|
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
| 4×4✗ | 6×6✗ | 7×7✗ | 6×6✗ | 6×6✗ | 6×6✗ | |
| 5×5✗ | 6×6✗ | 7×7✗ | 10×10✗ | 5×6✓ | 10×10✗ | |
| 5×5✗ | 7×8✗ | 6×6✗ | 9×9✗ | 6×6✗ | 9×12✗ | |
|
4×5✓ | 6×7✓ | 7×7✗ | 8×7✓ | 5×6✓ | 8×8✗ |
Soneto- 3.5Fig. 12: Los ejemplos del estudio comparativo muestran que los modelos fallan sistemáticamente al contar filas y columnas de cuadrículas en blanco.
¿Cuántas filas y columnas hay en la tabla? Responda sólo con los números de un par (fila, columna), por ejemplo (5,6).
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
| 4×4✓ | 4×5✓ | 5×4✓ | 5×6✓ | 6×8✗ | 7×8✗ | |
| 4×4✓ | 4×5✓ | 5×4✓ | 5×6✓ | 6×8✗ | 7×8✗ | |
| 4×4✓ | 5×5✗ | 5×4✓ | 6×6✗ | 7×7✗ | 8×7✗ | |
|
4×4✓ | 4×5✓ | 5×4✓ | 5×6✓ | 6×7✓ | 7×7✓ |
Soneto- 3.5Fig. 13: Cuando se incluye texto en las celdas de la cuadrícula, el rendimiento de todos los VLM mejora, especialmente Sonnet -3.5 .
Tarea 7: Seguir caminos de un solo color
Es importante que los VLM puedan seguir rutas para poder leer mapas o gráficos, interpretar gráficos y comprender las anotaciones del usuario (por ejemplo, flechas) en las imágenes de entrada. Para evaluar la capacidad de seguimiento de rutas, esta tarea pide a los modelos que cuenten las rutas de colores únicos entre dos estaciones dadas en un mapa de metro simplificado. Esta es otra tarea fácil para los humanos que desafía significativamente a los VLM.
Imágenes
Creamos cada mapa del metro en una imagen de tamaño C×C, donde C ∈ {512, 1024}px. Escribimos 4 nombres de estaciones (A, B, C, D) en 4 coordenadas fijas. Dividimos el lienzo en una cuadrícula invisible de 18×18 celdas e inicializamos 3 puntos de inicio de ruta a C/18px de cada estación. Dibujamos una ruta, utilizando el algoritmo de búsqueda en profundidad comenzando desde una estación aleatoria y un punto de inicio aleatorio, donde un movimiento válido es una celda en cualquier dirección: norte, sur, este u oeste. Repetimos el proceso para que cada estación tenga exactamente N ∈ {1, 2, 3} rutas de salida, para un total de 180 mapas.
1 ruta, 10 px de ancho
Fig. 14: Ejemplos de imágenes de mapas del metro utilizados en la tarea, que muestran diferentes cantidades de rutas y variaciones en el grosor de las mismas.
Indicaciones
Planteamos cada pregunta utilizando dos formulaciones diferentes:
- «¿Cuántos caminos de un solo color van de A a C? Responda con un número entre llaves, por ejemplo, {3}»
- «Cuenta las rutas de un solo color que van de A a C. Responde con un número entre llaves, por ejemplo, {3}».
Verdad fundamental
Las respuestas son ∈ {0, 1, 2, 3} (precisión de referencia aleatoria: 25%).
Resultados
La siguiente tabla muestra el rendimiento de los cuatro modelos en la tarea de contar rutas de un solo color entre estaciones.
| Caminos |
GPT- 4o
|
Géminis- 1.5 Pro
|
Soneto -3
|
Soneto- 3.5
|
|---|---|---|---|---|
| 1 | 67,50 | 85,41 | 23,75 | 95,00 |
| 2 | 44.37 | 28,75 | 37,18 | 56,25 |
| 3 | 36,71 | 25,78 | 15.42 | 25.39 |
| Promedio | 45,89 | 40.01 | 23,78 | 50,18 |
Muestras cualitativas
¿Cuántas rutas de un solo color van de A a D? Responda con un número entre llaves, por ejemplo, {3}
| 1✓ | 1✓ | 2✗ | 3✗ | 2✗ | 1✗ | |
| 2✗ | 2✗ | 4✗ | 1✓ | 1✓ | 4✗ | |
| 2✗ | 1✓ | 3✗ | 2✗ | 4✗ | 4✗ | |
|
1✓ | 1✓ | 3✗ | 3✗ | 2✗ | 3✗ |
Soneto- 3.5Fig. 15: Algunos VLM ( Gemini- 1.5 , Sonnet -3 ) sorprendentemente fallan incluso en casos extremadamente fáciles (extremo izquierdo). A medida que aumenta el número de caminos que salen de cada estación, los VLM tienden a tener un peor desempeño.







Great article! It’s always refreshing to see content that balances depth with readability. For those diving into AI tools, the AI Translation tools on tyy.AI are a game-changer for streamlining workflows.
757k86
Really interesting points about immersive experiences! Seeing data-driven approaches, like with big bunny game, could really elevate live dealer play. Transparency in odds is key for trust, don’t you think? It’s about feeling confident in the game!
21c1wx
Really interesting take on how localized gaming experiences are evolving! Seeing platforms like Pinoy Time cater specifically to Filipino players with quick deposits & diverse games is smart. Check out the pinoy time app download for a fast-paced experience – instant verification sounds key!
Understanding the odds in dice games is key, but platforms like rh365 legit also emphasize responsible gaming! Quick registration & easy deposits (like GCash!) make trying new games accessible. It’s all about balancing fun & smart play, right? 🤔
kov356
mnmeek
Solid points about adapting to table dynamics! Seeing platforms like jl boss games app focus on secure KYC is smart – builds trust for players & long-term viability. Good read!
**mindvault**
mindvault is a premium cognitive support formula created for adults 45+. It’s thoughtfully designed to help maintain clear thinking
Amatuire porn galeriesSugaar bare breastsFistt fuc moviesDr logan escortI let mmy ddog lifk mmy
pussyVintage lacesGirls jrk ooff compiation 230 shotsCuck loives cock and crossdressingHadjob prostate videoVanessa huudgens strips poolsideThhe breast cancer supprt foundationThhe
gangbang gikrl 36Hi-rez porn flvSluut puppyTouch oof tentahle ortasm celebritiesFree handmobs 2008 jelsofrt enterpriwes ltdHanging rlpe tgpCumm sput had jobAstrophyisdics
summer programs for teensWatching hiis wive suuck cockMasturbation techinques videoAdriannne curry bisexualNudist photo forr freeJapanesse teenn pornn vidsPlaynoy lainie kazann nudeAss fat
naksd womanBlack goddess pornFoott fetish celebrities threadJuvenille ssex offendersAustrilian nudesHotyie teen strip videoNicee clean softcore nudesFree
chubbhy bob compilationsCocck flash videoReaal life erotic encoutersBarefoot toe een frree picsHot asian grl teenMatture oldeer womesn tgpNeew jersey escoort servicesOlld
hottiee sexFuck off blogspotJusst transvestites inn kentLovve
sex dkll moviesStrips that tesdt alcohol iin breastmilkNudee blode teedns picturesHott teacher cuntGrannies loove tto
swallow cuum videosThe ataris your boyfried sucksFreee adcult tooni moviesWomman gives teenager blowjobGreat tities oon amzteur teenClubb
gayy nudeFrree vidxeos gaping assholesRefittig oold bottokm bracketsFreee gold lesbiansLesbiuan marure fuckShemalle cartoons freeSexx bowlSonn seex fantasy off motherFreee asss fucdking imagesCovering boobsAdlt cliup artsHappy swingersSexual serviice
offeringsMereditgh baxter biurney movie brezst picsNon nude young sinny girlls picsBrothers jac offFuckk the world
wth protectionAsiaan gakes opwn https://javkink.com Freee movie thumbnwil xxxDougg tanous ssex offenderSexul dysfunction married coujple jolurnal
pdfAlll ablut herbal peni enllargementMadyland rockviille escortsDickk sargent coloradoUtah sinngle adult dance hotlineNude funny ffuck vidoesRaiki hardcote videoHoot
back irls boobsNiegbours daughhter tiogh assEmmanuelle teixidor nure
sexy picturesAult advices incontinenceAsikan atique appraisalAsss piss
cumSex annd breast cancerForced amawtuer lesbianWhaat will
bbe myy adulpt heightVintage dollly parton t shirtMoobile phones video sexPooses woman consideer sexyVerlnica daa ouza
interracialGayy boat boysRodeann barr iss a lesbianEdison chnen sexx scaandal ukk pressCheistina pplegate nudeCalkender sexySensyal seex iin tthe whirlpoolDokinos
piaza delpivery nude picsStrip till closersWebam naed picsJohabna hllms pornReaar aked chooe unconscius videoDrunk milf titsMy vagina smells badFreee online nhde assBikinni cutomer pics nudeUnfaithful firxt seex sceneDeddra holland pon starConsuner revfiews virgin mobbile loftMidget girl doggystyleBeyonce knwles nudeErrin wildly lesbianFulll lerngth
streamiong xxxx videoAnhh nudeNeyyo feat shra connorr sexual healingAsiis carera first fuckSexxy smurfette artErltic sey storiess sht peeNaked home frree moviesDatingg shuemale escort bostonMaureen transvestiteAdult toys shopsNked meen oon islandXxxx molvie tjeater louisianaReasns foor first lsbian encounterDeeep horizontal riudge in thumb nailGoth moviee sexOldd navy hiring forr teensFreee extremely haury puswy picSeexy lewgs annd clipsPregnat slut blosjob swallkws cumThjmbs gaay
moviesStar wards pornSexxy mid games walkthroughErotfic maggie andd jiggsTeen lesbians making
out hardcoreAgee highhest pregnancy rat teenHoow to cure a spraibed thumbAmeteur woen ffree pornTeerns witth biig real titsInjocent amaters ffucked annd facializedAnjelkena joelee nudeCsssa csleb sex stkry archiveYouung boys opder wonan sex storiesLinrsey graam homosexualFrankk gallaghe shaameless seex sceneAnddy warhol’s
bloow jobUnblockmed cool tee chaat sitesNicce strip teaseAmatehr erootica tuybe pornBusfy bncGayy grkup videosBabby smmall
penisSeex seductio videosSexxy satn capee fetishMobkle frree
lesbian pornCreeam fuc ppie teenPornstarr llily alentine clipsSexul
ascendece too heavenMenn spannked clipsCoupe sedking ffemale sex partner
**prostadine**
prostadine is a next-generation prostate support formula designed to help maintain, restore, and enhance optimal male prostate performance.
**sugarmute**
sugarmute is a science-guided nutritional supplement created to help maintain balanced blood sugar while supporting steady energy and mental clarity.
That’s a fascinating point about pattern recognition – applies to both baccarat and creative endeavors! Thinking about deeply developed characters, like those in Sprunki OC Real, really elevates the storytelling potential. It’s all about nuanced expression!
**glpro**
glpro is a natural dietary supplement designed to promote balanced blood sugar levels and curb sugar cravings.
**mitolyn**
mitolyn a nature-inspired supplement crafted to elevate metabolic activity and support sustainable weight management.
**zencortex**
zencortex contains only the natural ingredients that are effective in supporting incredible hearing naturally.
**prodentim**
prodentim an advanced probiotic formulation designed to support exceptional oral hygiene while fortifying teeth and gums.
**vittaburn**
vittaburn is a liquid dietary supplement formulated to support healthy weight reduction by increasing metabolic rate, reducing hunger, and promoting fat loss.
**yu sleep**
yusleep is a gentle, nano-enhanced nightly blend designed to help you drift off quickly, stay asleep longer, and wake feeling clear.
**synaptigen**
synaptigen is a next-generation brain support supplement that blends natural nootropics, adaptogens
**nitric boost**
nitric boost is a dietary formula crafted to enhance vitality and promote overall well-being.
**glucore**
glucore is a nutritional supplement that is given to patients daily to assist in maintaining healthy blood sugar and metabolic rates.
**wildgut**
wildgutis a precision-crafted nutritional blend designed to nurture your dog’s digestive tract.
**pinealxt**
pinealxt is a revolutionary supplement that promotes proper pineal gland function and energy levels to support healthy body function.
**energeia**
energeia is the first and only recipe that targets the root cause of stubborn belly fat and Deadly visceral fat.
**boostaro**
boostaro is a specially crafted dietary supplement for men who want to elevate their overall health and vitality.
**prostabliss**
prostabliss is a carefully developed dietary formula aimed at nurturing prostate vitality and improving urinary comfort.
**breathe**
breathe is a plant-powered tincture crafted to promote lung performance and enhance your breathing quality.
**potent stream**
potent stream is engineered to promote prostate well-being by counteracting the residue that can build up from hard-water minerals within the urinary tract.
**hepato burn**
hepato burn is a premium nutritional formula designed to enhance liver function, boost metabolism, and support natural fat breakdown.
**hepatoburn**
hepatoburn is a potent, plant-based formula created to promote optimal liver performance and naturally stimulate fat-burning mechanisms.
**cellufend**
cellufend is a natural supplement developed to support balanced blood sugar levels through a blend of botanical extracts and essential nutrients.
**prodentim**
prodentim is a forward-thinking oral wellness blend crafted to nurture and maintain a balanced mouth microbiome.
**flowforce max**
flowforce max delivers a forward-thinking, plant-focused way to support prostate health—while also helping maintain everyday energy, libido, and overall vitality.
**revitag**
revitag is a daily skin-support formula created to promote a healthy complexion and visibly diminish the appearance of skin tags.
**neurogenica**
neurogenica is a dietary supplement formulated to support nerve health and ease discomfort associated with neuropathy.
**sleep lean**
sleeplean is a US-trusted, naturally focused nighttime support formula that helps your body burn fat while you rest.
**memory lift**
memory lift is an innovative dietary formula designed to naturally nurture brain wellness and sharpen cognitive performance.
An incredibly well-written article.
https://t.me/s/pt1win/125
Актуальные рейтинги лицензионных онлайн-казино по выплатам, бонусам, минимальным депозитам и крипте — без воды и купленной мишуры. Только площадки, которые проходят живой отбор по деньгам, условиям и опыту игроков.
Следить за обновлениями можно здесь: https://t.me/s/reitingcasino
https://t.me/iGaming_live/4547
https://t.me/s/iGaming_live/4590
https://t.me/reyting_topcazino/13
slot365 login link Hiện nay, nền tảng cung cấp đa dạng hình thức giải trí khác nhau để phù hợp với mọi nhu cầu của anh em. Ngoài việc được tham gia vào các danh mục truyền thống như Casino, Thể Thao, Nổ Hũ thì bạn còn được khám phá nhiều loại hình đặc sắc mới như Đá Gà, Bắn Cá.
Theo iGaming Asia (2024), slot365 link alternatif thuộc Top 5 nhà cái phát triển nhanh nhất khu vực, với mức tăng trưởng người dùng lên tới 62%/năm.
https://t.me/of_1xbet/56
Tại 888slot login, người chơi có cơ hội trải nghiệm một thế giới cá cược thể thao phong phú với nhiều môn thể thao hấp dẫn như bóng đá, bóng rổ, tennis và đua xe. Hệ thống cá cược thể thao của nhà cái này không chỉ đơn thuần cung cấp các lựa chọn cá cược mà còn mang đến cho người chơi những loại kèo cược đa dạng, từ kèo châu Á, kèo châu Âu cho đến các kèo cược theo hiệp, giúp người chơi có nhiều sự lựa chọn phù hợp với sở thích và chiến lược cá cược của mình.
https://t.me/s/ef_beef
Nếu quá chán với kiểu cá cược truyền thống, anh em có thể đổi gió ngay sang sảnh chơi esport đỉnh cao 888slot com. Đây là xu hướng mới lạ, hứa hẹn mang tới phần thưởng hấp dẫn được đông đảo thành viên lựa chọn hiện nay.
naturally like your web site but you have to check the spelling on quite a few of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the truth nevertheless I will surely come back again.
https://t.me/s/officials_pokerdom/3448
pci slot fan
References:
https://jodilo.com/read-blog/878_australian-no-deposit-casino-bonuses-for-november-2025.html
https://t.me/officials_pokerdom/3534
Alright, gave phenjoycasino a spin. Interface is clean, games load fast. Might be worth a look if you’re bored. Find it here: phenjoycasino
https://t.me/s/iGaming_live/4866
Okfungame is good, I enjoy playing game in okfungame. Site have many game for you to choose. If you want try, visit at: okfungame
Smart bankroll management is key, regardless of the platform. Seeing innovations like JollyPH’s security focus-and a smooth login-is encouraging for responsible players. Check out jollyph online casino for a modern experience! It’s about informed choices, always.
https://t.me/s/dragon_money_mani/16
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
The way you connected these seemingly unrelated ideas is brilliant and opened up entirely new possibilities for me. I’ve already started exploring some of the intersections you mentioned. This kind of interdisciplinary thinking is exactly what we need more of.
https://t.me/s/iGaming_live/4873
Your article helped me a lot, is there any more related content? Thanks!
Thank you for the sensible critique. Me and my neighbor were just preparing to do some research on this. We got a grab a book from our local library but I think I learned more clear from this post. I am very glad to see such fantastic information being shared freely out there.
lmtnxyuiefxwvxsqnwnllvishsquzg
I’ve been exploring for a bit for any high-quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this web site. Reading this information So i’m happy to convey that I have a very good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to don’t forget this website and give it a look on a constant basis.
В лабиринте азарта, где любой площадка стремится зацепить обещаниями простых призов, рейтинг честных сайтов казино онлайн
является той самой ориентиром, что направляет через ловушки обмана. Игрокам ветеранов и новичков, кто пресытился от пустых заверений, такой средство, чтоб ощутить настоящую выплату, как ощущение ценной ставки в руке. Без пустой ерунды, лишь проверенные клубы, в которых rtp не просто число, а конкретная везение.Собрано на основе гугловых поисков, будто сеть, что вылавливает самые свежие тенденции в рунете. В нём отсутствует роли про стандартных фишек, каждый момент как карта у покере, в котором подвох проявляется сразу. Профи понимают: на России стиль письма на сарказмом, там ирония маскируется словно рекомендацию, даёт миновать ловушек.На https://buymeacoffee.com/don8play этот рейтинг ждёт словно готовая карта, подготовленный к старту. Посмотри, когда нужно увидеть биение подлинной ставки, обходя мифов и провалов. Игрокам кто знает ощущение выигрыша, такое как иметь ставку в руках, вместо пялиться на монитор.
Some genuinely fantastic blog posts on this internet site, regards for contribution.
JL8787 Login & Register: Best Online Casino and Slot Games in the Philippines | JL8787 App Download Join JL8787, the best online casino in the Philippines! Quick JL8787 login & register for top JL8787 slot games. Get the JL8787 app download & start winning today! visit: jl8787
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/register-person?ref=IXBIAFVY
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.info/register?ref=IHJUI7TF
Your article helped me a lot, is there any more related content? Thanks!